Two years ago at One Mighty Roar we noticed that a side-project from the early days of the company was gaining large amounts of traffic, despite not being touched in ages. Over the process of a few months, we spent some 20% time, which quickly turned into 120% time, revamping You Rather, redoing the site from the ground up, creating an API, and writing both an iOS and an Android app. As a result, You Rather has done some excellent numbers, gained some community garnishment, and been a great project for the OMR team to boast about. But, as most side-projects are, they fall low on the priority list when other new opportunities come along.
At the end of this summer, it became our goal to give You Rather a breath of new life. The first step was to axe the aged Apache HTTP server in favor of Nginx. We’ve been using Nginx for 99% of our work over the last year and haven’t looked back since. However, most of our Nginx experience has been writing .conf files for new sites and servers, never rewriting old .confs for existing production sites.
In just an afternoon, we moved a site with 400+ active concurrent users doing 1k+ pageviews a second, from Apache to Nginx, without any downtime.
Brushing off the Dust
To give some background, we ♥ AWS. You Rather uses every bit of the AWS stack, from EC2 to EBS to Route 53 to S3. To get a “dev” environment setup for ourselves, we grabbed our current AMI of the You Rather site and spun up a new instance for us to hack on.
A simple yum install nginx got us Nginx up and running on our CentOS box in no time. Step one, complete.
To start, we tossed up our generic Nginx conf:
Lo and behold, most things…just worked. Granted, we had done plenty of work getting the AMI setup with with Apache and PHP initially, switching over to Nginx was pretty easy to get started. Step two, complete.
Tweaking for Performance
Nginx has a few obvious benefits over Apache when it comes to the server layer, but Nginx isn’t the sole reason for You Rather’s performance improvement. To see why, let’s clarify what exactly makes the difference here.
Where Nginx really shines is that it doesn’t process “.htaccess” files. While those files make for convenient setups on shared hosting plans or shared machines, traversing the file directory for those files occurs on each request, which gets expensive. Nginx, on the other hand, loads all configs in at launch and that’s it, you’re good to go.
Another place we saw had room for improvement was the interaction between our webserver and PHP. Our current implementation of You Rather used mod_php with Apache. Although the initial setup for Apache and mod_php was quick and easy, a big disadvantage to this is the way PHP is processed per request. Opting for PHP-FPM in favor of mod_php gave us significant performance boosts. Where as mod_php was interpreting PHP as a part of the Apache process, quickly soaking up large amounts of CPU and memory, PHP-FPM can be fine tuned to get great performance benefits. Utilizing PHP processes that are gracefully launched and killed, Unix sockets, and granular process management, PHP-FPM helped us tune back our overall resource usage on the box. On top of all of these tweaks, now we can tweak configurations for Nginx without affecting PHP-FPM and vice versa without breaking one or the other.
As one last golden bullet to tweak the performance of PHP, we added an opcode cache. Testing out Zend OPCache and APC, we found that OPCache kicked it out of the park for us, boosting PHP processing time and reducing memory consumption overall.
Step three, complete.
Sieging the Site
One thing we’ve gotten better at as a result of You Rather’s traffic is testing our apps under heavy load. On any given day, we’ve experienced large traffic spikes due to social media, aggregators (see: the Slashdot effect), or App Store features. Two tools we use a lot to test load handling are siege, and ab. For this setup, we mostly used siege.
Once we got Nginx serving our site up just right on our dev instance, it was time to hammer the box to see what it could handle. Using siege, we could see what kind of a load a single instance could handle. One great advantage of siege is its ability to hit an endpoint with concurrent connections, perfect for simulating a real-world use-case of You Rather. Starting the command:
We simulated 20 concurrent users ( -c 20) hitting the site on that instance, non-stop for a minute ( -t 1M). siege gives great analysis of the tests both during and afterwards. Things looked great from the get-go. The throughput was much lower than the old Apache AMI, and response times were generally lower. We kept tweaking the siege test, varying between 10 to 100 or more concurrent connections (protip: don’t go over 75 connections generally, things will break…), hitting different endpoints, like the user profile page, a specfic question’s page, and even the 404 page.
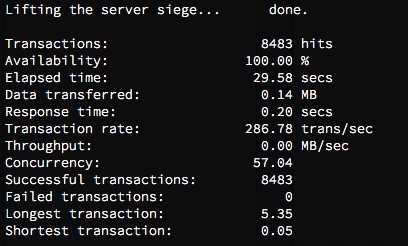
We compared the results from siege’ing the Nginx instance to a version of the current Apache site running on a control instance. In short, the Nginx instance performed 100% more transactions, with 50% less response time per transaction. Better yet, we watched the topon the Nginx box while testing this out. It handled it like a boss, barely topping out the CPU while slamming it with connections. Nginx was clearly giving the site the boost it needed.
Going Live
Using all of the glory that is AWS, we already had load balancers set up for the site, as well as auto-scaling groups and rules in place for killing unhealthy instances and spinning new ones up where needed. In our search for keeping the site available as much as possible, spinning up new instances under heavy load can get expensive.
Once we made a new AMI for the new deployment of the site, it was time to tweak the auto-scale group to spin up new instances from the new AMI. Using the AWS CLI, we just set the group to spin new instances up from the new AMI. Next, we set the number of desired instances for the group to a healthy number that we knew wouldn’t crash the site, leaving room for a mix of Apache and Nginx instances to be balanced side-by-side.
From here, we slowly killed off the old Apache instances one by one manually, letting the auto-scale group spin a new Nginx instance up in its place. Meanwhile, watching Google Analytics, we still had thousands of pageviews and API calls happening per second, live to the site, including the new Nginx boxes.
Finally, not a single Apache box was left load balanced, we started scaling back the number of desired instances for the group. From 4… to 3… to 2… We probably could have run it all off one box, but for the sake of our own sanity, 2 sounded right.
A week later, we had a bit of a post-mortem, analyzing the numbers. Guess where the Nginx revamp happened:

Our varying number of instances is more or less static now, and has been for weeks:

We have now been serving millions of pageviews and API calls off of two Nginx instances with 0% downtime for a solid three weeks now. Sorry Apache, there’s no looking back.
No comments:
Post a Comment