A problem with pcntl_fork - PHP:
The OS keeps the zombie around in case the parent process eventually
decides to retrieve the child's exit status information. You can tell
the OS you're not interested and to not keep zombies around using this:
pcntl_signal(SIGCHLD, SIG_IGN);
You could also trap SIGCHLD and check the child's exit status:
function sigchld($signo) {
while (($pid = pcntl_waitpid(-1, $status, WNOHANG)) 0) {
echo "Child with PID $pid returned " .
pcntl_wexitstatus($status) . ".\n";
}
}
pcntl_signal(SIGCHLD, 'sigchld');
Thursday, May 23, 2013
Friday, May 10, 2013
Redis Administration – Redis
Redis Administration – Redis:
Redis Administration
This page contains topics related to the administration of Redis instances. Every topic is self contained in form of a FAQ. New topics will be created in the future.
Redis setup hints
- We suggest deploying Redis using the Linux operating system. Redis is also tested heavily on osx, and tested from time to time on FreeBSD and OpenBSD systems. However Linux is where we do all the major stress testing, and where most production deployments are working.
- Make sure to set the Linux kernel overcommit memory setting to 1. Add
vm.overcommit_memory = 1to/etc/sysctl.confand then reboot or run the commandsysctl vm.overcommit_memory=1for this to take effect immediately. - Make sure to setup some swap in your system (we suggest as much as swap as memory). If Linux does not have swap and your Redis instance accidentally consumes too much memory, either Redis will crash for out of memory or the Linux kernel OOM killer will kill the Redis process.
- If you are using Redis in a very write-heavy application, while saving an RDB file on disk or rewriting the AOF log Redis may use up to 2 times the memory normally used. The additional memory used is proportional to the number of memory pages modified by writes during the saving process, so it is often proportional to the number of keys (or aggregate types items) touched during this time. Make sure to size your memory accordingly.
- Even if you have persistence disabled, Redis will need to perform RDB saves if you use replication.
- The use of Redis persistence with EC2 EBS volumes is discouraged since EBS performance is usually poor. Use ephemeral storage to persist and then move your persistence files to EBS when possible.
- If you are deploying using a virtual machine that uses the Xen hypervisor you may experience slow fork() times. This may block Redis from a few milliseconds up to a few seconds depending on the dataset size. Check the latency page for more information. This problem is not common to other hypervisors.
- Use
daemonize nowhen run under daemontools.
Upgrading or restarting a Redis instance without downtime
Redis is designed to be a very long running process in your server. For instance many configuration options can be modified without any kind of restart using the CONFIG SET command.
Starting from Redis 2.2 it is even possible to switch from AOF to RDB snapshots persistence or the other way around without restarting Redis. Check the output of the 'CONFIG GET *' command for more information.
However from time to time a restart is mandatory, for instance in order to upgrade the Redis process to a newer version, or when you need to modify some configuration parameter that is currently not supported by the CONFIG command.
The following steps provide a very commonly used way in order to avoid any downtime.
- Setup your new Redis instance as a slave for your current Redis instance. In order to do so you need a different server, or a server that has enough RAM to keep two instances of Redis running at the same time.
- If you use a single server, make sure that the slave is started in a different port than the master instance, otherwise the slave will not be able to start at all.
- Wait for the replication initial synchronization to complete (check the slave log file).
- Make sure using INFO that there are the same number of keys in the master and in the slave. Check with redis-cli that the slave is working as you wish and is replying to your commands.
- Configure all your clients in order to use the new instance (that is, the slave).
- Once you are sure that the master is no longer receiving any query (you can check this with the MONITOR command), elect the slave to master using the SLAVEOF NO ONE command, and shut down your master.
Tuesday, May 7, 2013
php - MySQL: Get total number of rows when using LIMIT - Stack Overflow
MySQL: Get total number of rows when using LIMIT
A
SELECT statement may include a LIMIT clause to restrict the number of rows the server returns to the client. In some cases, it is desirable to know how many rows the statement would have returned without the LIMIT, but without running the statement again. To obtain this row count, include a SQL_CALC_FOUND_ROWS option in theSELECT statement, and then invoke FOUND_ROWS() afterward:mysql>SELECT SQL_CALC_FOUND_ROWS * FROM->tbl_nameWHERE id > 100 LIMIT 10;mysql>SELECT FOUND_ROWS();
The second
SELECT returns a number indicating how many rows the first SELECT would have returned had it been written without the LIMIT clause.
In the absence of the
SQL_CALC_FOUND_ROWS option in the most recent successful SELECT statement,FOUND_ROWS() returns the number of rows in the result set returned by that statement. If the statement includes aLIMIT clause, FOUND_ROWS() returns the number of rows up to the limit. For example, FOUND_ROWS() returns 10 or 60, respectively, if the statement includes LIMIT 10 or LIMIT 50, 10.
The row count available through
FOUND_ROWS() is transient and not intended to be available past the statement following the SELECT SQL_CALC_FOUND_ROWS statement. If you need to refer to the value later, save it:mysql>SELECT SQL_CALC_FOUND_ROWS * FROM ... ;mysql>SET @rows = FOUND_ROWS();
If you are using
SELECT SQL_CALC_FOUND_ROWS, MySQL must calculate how many rows are in the full result set. However, this is faster than running the query again without LIMIT, because the result set need not be sent to the client.SQL_CALC_FOUND_ROWS and FOUND_ROWS() can be useful in situations when you want to restrict the number of rows that a query returns, but also determine the number of rows in the full result set without running the query again. An example is a Web script that presents a paged display containing links to the pages that show other sections of a search result. Using FOUND_ROWS() enables you to determine how many other pages are needed for the rest of the result.
The use of
SQL_CALC_FOUND_ROWS and FOUND_ROWS() is more complex for UNION statements than for simpleSELECT statements, because LIMIT may occur at multiple places in a UNION. It may be applied to individualSELECT statements in the UNION, or global to the UNION result as a whole.
The intent of
SQL_CALC_FOUND_ROWS for UNION is that it should return the row count that would be returned without a global LIMIT. The conditions for use of SQL_CALC_FOUND_ROWS with UNION are:- The value of
FOUND_ROWS()is exact only ifUNION ALLis used. IfUNIONwithoutALLis used, duplicate removal occurs and the value ofFOUND_ROWS()is only approximate.
Wednesday, May 1, 2013
Creating a Chat server in PHP with sockets, forks and pipes | Systems Architect
Creating a Chat server in PHP with sockets, forks and pipes | Systems Architect:

In my previous post I showed how to create a multi process socket server in PHP with pcntl_fork. This time I’m going to extend this example and write a chat server.
Chat is far more challenging because you not only have to handle simultaneous connections but also allow communications between processes. Inter process communication (IPC) has to be close to real time, synchronized and safe from racing condition.
Before I continue let me say the example I’m going to show won’t work on Windows. It use POSIX extension which is available only on Linux-like environments.
As previously you can download the code from GitHub and try it.
From different terminals
To see how it works you need at least two telnet sessions. When a messages is typed on one of them it should be immediately broadcasted to the others.
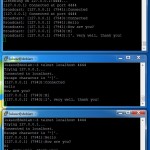
SocketServerBroadcast (which extends SocketServer) is heart of the application and is handled by parent process. The Parent is responsible for listening for a new connections, maintaining list of active connections and sending broadcast on a child process request.
Client connections are handled by callback “onConnect()” in server-broadcast.php. When data is received an instance of SocketClientBroadcast wraps it into an array and sends it via pipe to the parent process. The code which actually sends the data is inside SocketServerBroadcast.
To tell the parent which child send a message a PID key is added to the message array. Pipe works like a file so the array has to be converted to a string. Serialiaze() is perfect for the job. The parent listening on the other side of the pipe is unable to figure out how long a message is going to be. The child has to tell him. In order to achieve that every first 4 bytes in every message are representing an integer. The integer carries a length of the message.
Finally, when data is sent the child has to inform the parent there is a message for him.
Posix_kill() send a SIGUSR1 signal to $this->pid which holds the parent process id.
SocketServerBroadcast register SIGUSR1 in beforeServerLoop method.
It also set the socketServer to work in a nonblocking mode. By default socket_accept() waits for a new connection and is blocking process execution. When the nonblocking mode is on, socket_accept() checks is there any new connection at a certain moment. If there isn’t it throws a warning and continues execution.
In the main loop the server check is there a connection and if not it wait 1 second for a SIGUSR1 signal. When signal is sent pcntl_sigtimedwait() returns immediately and $this->handleProcess() is executed.
Before the parent acquire a message from the pipe is has to know how long the message is. As you remember first 4 bytes hold the length.
Following code is straight forward. Read the actual message, unserialize and handle it.
That would be it. You can extend this example and create much complex application. Be cautious that the pipe communication strictly relies on [HEADER][MESSAGE] pattern. If for any reason header value will get incorrect the application will not recover. For a real live server I would suggest to implement a solution to mitigate header corruption.
Creating a Chat server in PHP with sockets, forks and pipes
In my previous post I showed how to create a multi process socket server in PHP with pcntl_fork. This time I’m going to extend this example and write a chat server.
Chat is far more challenging because you not only have to handle simultaneous connections but also allow communications between processes. Inter process communication (IPC) has to be close to real time, synchronized and safe from racing condition.
Before I continue let me say the example I’m going to show won’t work on Windows. It use POSIX extension which is available only on Linux-like environments.
As previously you can download the code from GitHub and try it.

SocketServerBroadcast (which extends SocketServer) is heart of the application and is handled by parent process. The Parent is responsible for listening for a new connections, maintaining list of active connections and sending broadcast on a child process request.
Client connections are handled by callback “onConnect()” in server-broadcast.php. When data is received an instance of SocketClientBroadcast wraps it into an array and sends it via pipe to the parent process. The code which actually sends the data is inside SocketServerBroadcast.
SocketServerBroadcast register SIGUSR1 in beforeServerLoop method.
That would be it. You can extend this example and create much complex application. Be cautious that the pipe communication strictly relies on [HEADER][MESSAGE] pattern. If for any reason header value will get incorrect the application will not recover. For a real live server I would suggest to implement a solution to mitigate header corruption.
Subscribe to:
Posts (Atom)